One of the most often-used features of the Cloud Elements platform is the bulk APIs, available and standardized within each element. These APIs allow a developer to upload or download a batch of records, typically via a Comma Separated Variable (CSV) file, but also as a JSONL or JSON payload. Certain resources, e.g. invoices, where the number of attributes/fields/columns in a record can be variable across multiple records, only JSON can be supported for bulk uploads and downloads.
Although very powerful for transferring large batches of data between an application and a service, it is crucial to note that the bulk APIs are built to be used asynchronously. That means that when a UI application invokes a bulk API, the application should not expect to, and will not, receive the first page of records back as a synchronous API such as GET /contacts would. The bulk API will instead return a bulk job ID for a scheduled job, which will be executed at a future time (typically less than a minute after scheduling), and the scheduled job will in turn synchronously invoke the GET /contacts API with a pagination cursor to retrieve all the queried or requested records.
UI Application for Bulk APIs
The following illustration shows how bulk APIs should be used from a UI application, in this example for retrieving/downloading batch data.
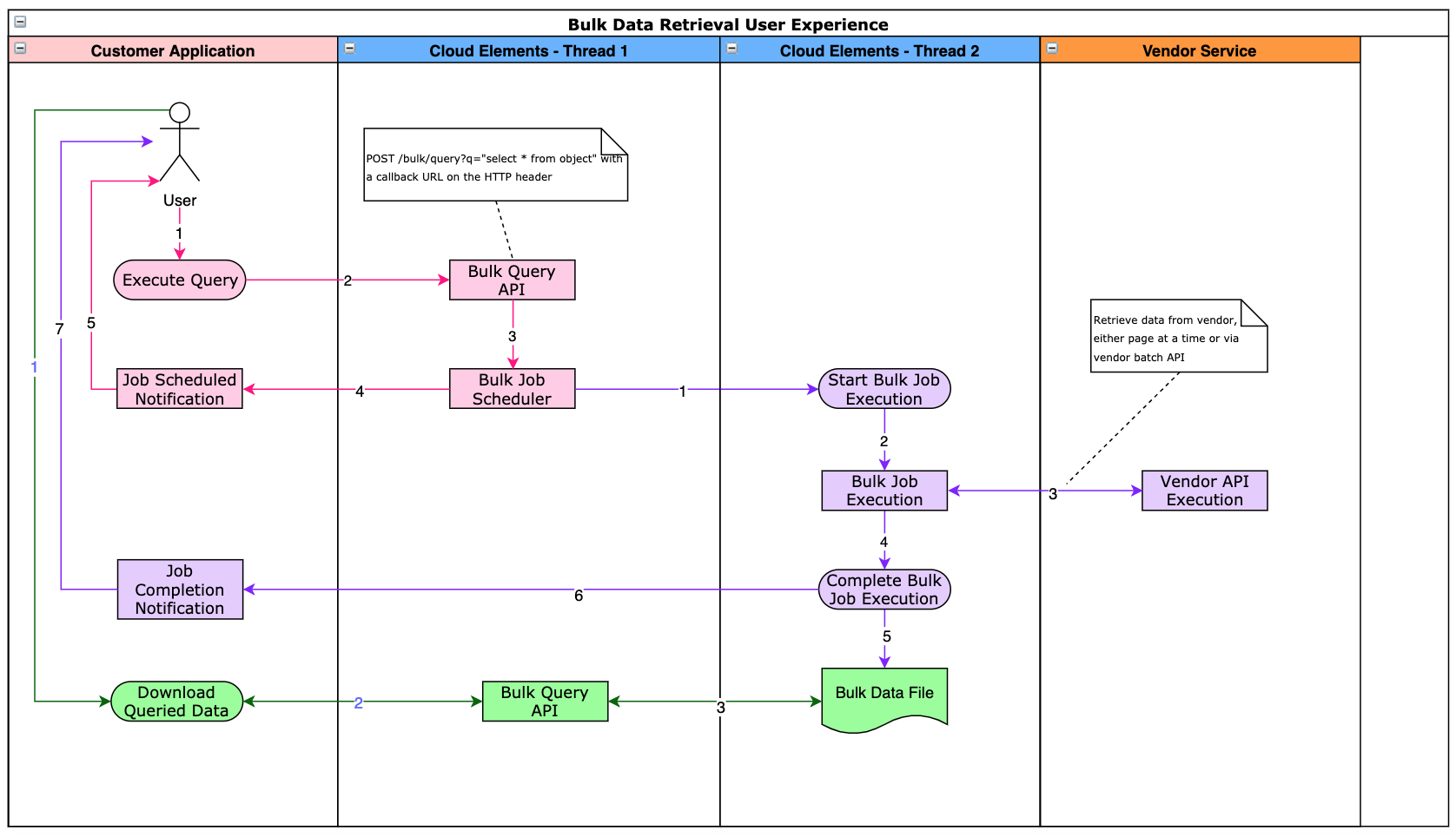
Figure 1
There are three domains for when using bulk APIs from a UI application
- The UI Application domain
- The Cloud Elements Platform
- The Vendor Service
There are two distinct flows that span the above three domain, which are executed in one or more of the domains.
- The bulk query request and execution
- The data download request
Bulk Query Request and Execution
The user of the UI application will invoke the bulk query request. This will typically involve entering some filter criteria, e.g. retrieve all contacts that were created between Jan 1, 2018 and Jan 1, 2019. In some cases, when all the data from a given system needs to be retrieved, there won't be any filters specified. Once the user enters the filter criteria and submits the request, the UI application will invoke the POST /bulk/query API for the element instance. The q query parameter for this API will be populated with a CEQL statement indicating the resource, e.g. contacts and filters that the user entered in the UI as where clause parameters. For example, the bulk query API issued against the element instance may be as follows.
POST /bulk/query?q='select * from contacts'&from=2018-01-01T00:00:00Z&to=2019-01-01T00:00:00ZWhen the above API is invoked, a bulk job will be started asynchronously on a new thread in the Cloud Elements platform and the bulk job ID will be returned immediately in the response to the bulk query above. When the UI application receives the response from the issued bulk query, the best practice is for the UI application to notify the user that her job has been scheduled for execution, and that the user will be notified when the job is completed and the data is available to download. Following is an example of the response from the bulk query.
{
"instanceId": 16358,
"id": "5576852",
"status": "CREATED"
}When the bulk job is executed, the corresponding vendor API for the requested resource is executed. For example, if the element instance is one for the Magento 2.0 element, and the requested resource is customers, then the Customers resource endpoint at Magento.com is utilized for execution.
If the vendor API support batch execution, e.g. Pardot, then the batch API is used, resulting in another asynchronous execution chain, but the developer of the UI application does not have to concern herself with this, as the Cloud Elements platform manages this on her behalf.
If the vendor API does not support batch execution, then the Cloud Elements platform executes the requested query against the vendor API, translating the CEQL filters to that required by the vendor API, and paginates through the results, saving them, in the Cloud Elements platform, in an encrypted file belonging to the requesting UI application.
Starting multiple bulk query requests to try and parallelize data retrieval will not make the retrieval process any faster; as a matter fact, it could have the opposite effect, as vendors usually rate limit API calls, including batch requests.
When all the requested data has been retrieved and persisted to the file, or there is an error at the service provider's end, the status of the bulk job is marked as COMPLETED and the data is available for download (if the job was successful) by the UI application for the next 10 days.
There are a couple of approaches that can be taken to allow the UI application to know when the bulk job is complete.
- To launch a background task thread to check the status of the bulk job periodically
- To provide a callback endpoint URL via the bulk query
The preferred approach, i.e. the best practice, is to use #2 above. In order to do so, the following header can be provided on the bulk query API
Elements-Async-Callback-Url: https://sample.example.com/bulk/callbackThe above specified URL, i.e. https://sample.example.com/bulk/callback, is only an example URL and not a real endpoint.
When the above header is specified, the scheduled bulk job will invoke the provided callback URL via a POST, with the status of the bulk job, once it has completed. The time elapsed between when the bulk query was started and when the developer receives the callback notification will depend on the query performance at the service provider's endpoint, and the volume of data retrieved. Typically, the callback to the developer will occur after a minute after the job has completed, either successfully or with an error. Using the callback mechanism will allow the developer to avoid having to use a background task in the UI application code, which is too dependent on the browser window running, among other factors, that could adversely affect the usability and user experience.
If the developer prefers to use approach #1 above, i.e. to launch a background task thread in the UI application, then the developer can invoke the following API to check the status of the bulk job periodically.
GET /bulk/{id}/statusFor the status API above, the {id} field will contain the bulk job ID returned from the bulk query. Following is an example of a response from he status API.
{
"recordsCount": 1,
"metadata": "{\"composite\":false,\"query\":\"select * from contacts where FirstName like 'Test%'\",\"version\":\"1\"}",
"recordsFailedCount": 0,
"instanceId": 16358,
"vendorJobId": "7500H00000JbjQTQAZ",
"fileSize": 3472,
"object_name": "Contact",
"job_direction": "DOWNLOAD",
"id": "5576852",
"bulk_start_time": "2019-03-14T00:29:20.788Z",
"fileFormat": "csv",
"status": "COMPLETED"
}The status attribute in the above example can be used to determine if the job is complete or not.
Data Download Request
The final activity to be completed by the UI application developer is to allow the user of the UI to initiate the data download request. When the bulk job completion callback URL as described above is invoked, the UI application can notify the user with a URL that includes the bulk job ID, which when selected by the user can initiate the final request chain. In doing so, the UI application will invoke the following element instance endpoint.
GET /bulk/{id}/{objectName}In our example, the {objectName} is contacts and the {id} is that of the bulk job as described above. This request will result in the contents of the data file being streamed back to the UI application, which in turn can allow the user to save the file to her laptop or among other possibilities, can upload the content to a database, for the user to use. Basically, at this point the requested data is available to the UI application to use as it chooses to do so.
The GET /bulk/{id}/{objectName} API call can take an optional "Accept" header specifying the mime type or content type of the data. For example when a mime type of "text/csv" is specified, the queried data is returned in CSV format.
Additionally, this API call expects to return the data as multipart form content, so the UI application needs to be prepared to handle such data in the response.
Summary
The bulk APIs provided by the Cloud Elements platform are very powerful as they allow an application developer to perform batch operations even if the vendor API does not support such operations. However, the bulk APIs, like all other batch data APIs, are designed to operate asynchronously, so should be utilized as such via the best practices specified in this document. Utilizing the bulk APIs synchronously will result in a poor user experience for the end user, as the time to completion of the bulk job can be fairly long depending on the volume of the data and can also be indeterministic depending on whether job execution threads are available immediately or not, to the job scheduler.
